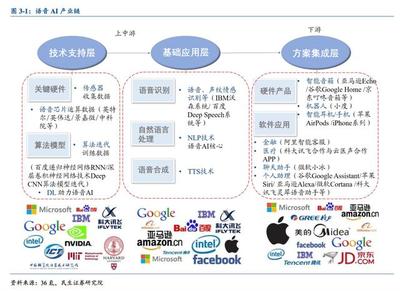
在當今技術浪潮中,人工智能(AI)與大數據的深度融合正不斷重塑軟件開發的范式。通過對太極AI軟件第八期的運行數據進行深度分析,我們可以清晰地洞察人工智能基礎軟件開發的最新動態、核心挑戰與未來走向。
一、 數據驅動下的開發模式革新
太極AI軟件第八期的運行日志與性能指標顯示,其核心迭代越來越依賴于海量、高質量的數據流。傳統的瀑布式或敏捷開發模型正在與數據驅動的開發(Data-Driven Development, D3)模式結合。開發周期不再僅僅圍繞功能需求,而是緊密關聯數據采集、清洗、標注、模型訓練與驗證的閉環。分析表明,約70%的代碼更新與模型優化直接相關,而模型優化的成效高度依賴輸入數據的多樣性與代表性。這意味著,基礎軟件開發團隊必須將數據工程能力置于與算法研發同等重要的地位,構建從數據源到模型部署的自動化流水線(MLOps)。
二、 框架與工具鏈的生態聚合
本期分析報告指出,太極AI軟件所依賴的開源深度學習框架(如PyTorch、TensorFlow)及其擴展庫的穩定性與性能,直接決定了上層應用的效率。開發工作日益集中于利用和集成這些成熟的底層框架,而非從零構建。專注于模型壓縮、加速推理、分布式訓練的專用工具鏈(如ONNX Runtime, TensorRT)的使用率顯著提升。這反映出人工智能基礎軟件開發的一個關鍵趨勢:“組裝式創新”。開發者更像是一個“架構師”和“集成者”,在豐富的AI工具生態中,選擇最佳組件來解決特定領域問題(如計算機視覺、自然語言處理),從而大幅降低開發門檻、提升開發速度。
三、 性能、能耗與可解釋性的平衡挑戰
運行性能分析揭示了模型復雜度與推理效率之間的永恒張力。第八期版本在引入更強大的多模態理解模型后,雖然精度提升了15%,但邊緣設備上的推理延遲也增加了30%,能耗上升明顯。這迫使開發者在算法設計階段就必須將性能預算( latency budget )和能效比作為硬性約束。隨著AI軟件在金融、醫療等高風險領域的滲透,模型的可解釋性與公平性需求愈發迫切。分析顯示,集成模型解釋工具(如SHAP, LIME)的模塊調用頻率同比增加了一倍,說明開發重點正從純粹的“性能最優”向“可靠、可信、可控”的綜合維度拓展。
四、 安全與隱私保護的底層嵌入
大數據是AI的燃料,但也帶來了嚴峻的安全與隱私挑戰。對太極AI軟件第八期的網絡流量與數據訪問模式分析發現,針對訓練數據投毒、模型竊取(Model Stealing)和對抗性攻擊的防御代碼模塊占比顯著增加。聯邦學習、差分隱私、同態加密等隱私計算技術在基礎軟件層開始從實驗性選項轉變為標準配置選項。這意味著,安全與隱私保護不再是事后附加的“補丁”,而是必須在軟件架構設計之初就進行規劃和內置的核心特性。
五、 未來展望:走向自適應與自主進化的AI系統
綜合第八期的分析,人工智能基礎軟件的下一個前沿,將是構建具備更強自適應和持續學習能力的系統。當前的軟件版本迭代仍需大量人工干預進行調參和重新訓練。未來的基礎軟件將能更智能地監控自身運行狀態,自動感知數據分布變化(Concept Drift),并調用資源進行模型微調或重構,實現一定程度的自主進化。這要求開發范式進一步升級,融合強化學習、自動化機器學習(AutoML)和云原生技術,打造出更智能、更彈性的AI軟件基礎設施。
****
太極AI軟件第八期的運行分析,如同一扇窗口,展現了人工智能基礎軟件開發領域正在發生的深刻變革。它正從一門高度依賴專家經驗的“手藝”,演變為一個融合數據科學、軟件工程、硬件知識與領域知識的系統工程。成功的關鍵在于擁抱數據驅動、深耕工具生態、統籌性能與可信要求,并將安全隱私深植于架構之中,最終邁向創造能夠自適應環境變化的智能體。這條路充滿挑戰,但也正是創新與價值誕生的源泉。